概述
KNN可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一,注意KNN算法是有监督学习中的分类算法,它看起来和另一个机器学习算法Kmeans有点像(Kmeans是无监督学习算法),但却是有本质区别的。那么什么是KNN算法呢,接下来我们就来介绍介绍吧。
原理介绍
KNN的全称是K Nearest Neighbors,KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
下面通过一个简单的例子说明一下:
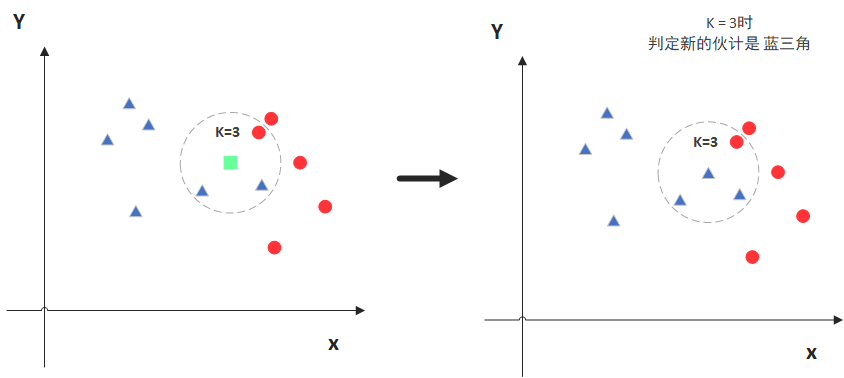
图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
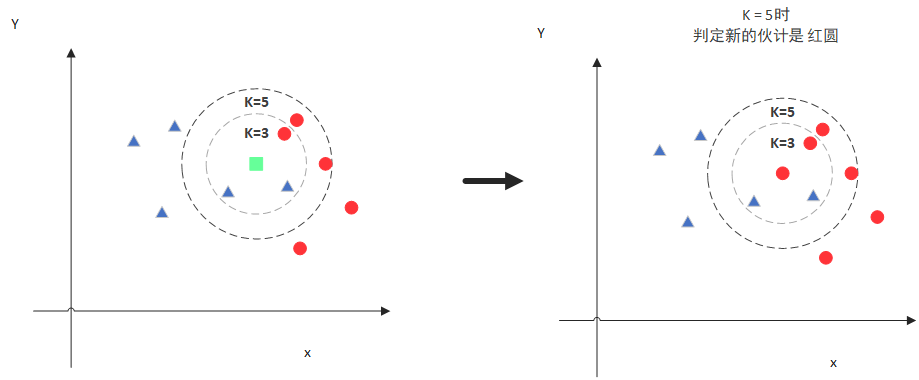
但是,当K=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。从这个例子中,我们就能看得出K的取值是很重要的。
明白了大概原理后,我们就来说一说细节的东西吧,主要有两个,K值的选取和点距离的计算。
距离计算
要度量空间中点距离的话,有好几种度量方式,比如常见的曼哈顿距离计算,欧式距离计算等等。不过通常KNN算法中使用的是欧式距离,这里只是简单说一下,拿二维平面为例,,二维空间两个点的欧式距离计算公式如下:

这个高中应该就有接触到的了,其实就是计算(x1,y1)和(x2,y2)的距离。拓展到多维空间,则公式变成这样:

这样我们就明白了如何计算距离,KNN算法最简单粗暴的就是将预测点与所有点距离进行计算,然后保存并排序,选出前面K个值看看哪些类别比较多。但其实也可以通过一些数据结构来辅助,比如最大堆,这里就不多做介绍,有兴趣可以百度最大堆相关数据结构的知识。
K值选择
通过上面那张图我们知道K的取值比较重要,那么该如何确定K取多少值好呢?答案是通过交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据),从选取一个较小的K值开始,不断增加K的值,然后计算验证集合的方差,最终找到一个比较合适的K值。
通过交叉验证计算方差后你大致会得到下面这样的图:
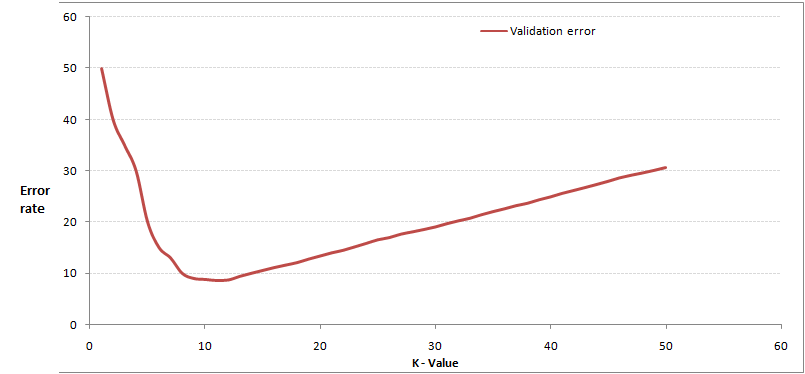
这个图其实很好理解,当你增大k的时候,一般错误率会先降低,因为有周围更多的样本可以借鉴了,分类效果会变好。但注意,和K-means不一样,当K值更大的时候,错误率会更高。这也很好理解,比如说你一共就35个样本,当你K增大到30的时候,KNN基本上就没意义了。
所以选择K点的时候可以选择一个较大的临界K点,当它继续增大或减小的时候,错误率都会上升,比如图中的K=10。具体如何得出K最佳值的代码,下一节的代码实例中会介绍。
KNN特点
KNN是一种非参的,惰性的算法模型。什么是非参,什么是惰性呢?
非参的意思并不是说这个算法不需要参数,而是意味着这个模型不会对数据做出任何的假设,与之相对的是线性回归(我们总会假设线性回归是一条直线)。也就是说KNN建立的模型结构是根据数据来决定的,这也比较符合现实的情况,毕竟在现实中的情况往往与理论上的假设是不相符的。
惰性又是什么意思呢?想想看,同样是分类算法,逻辑回归需要先对数据进行大量训练(tranning),最后才会得到一个算法模型。而KNN算法却不需要,它没有明确的训练数据的过程,或者说这个过程很快。
KNN算法的优势和劣势
KNN算法优点
- 简单易用,相比其他算法,KNN算是比较简洁明了的算法。即使没有很高的数学基础也能搞清楚它的原理。
- 模型训练时间快,上面说到KNN算法是惰性的,这里也就不再过多讲述。
- 预测效果好。
- 对异常值不敏感
KNN算法缺点
- 对内存要求较高,因为该算法存储了所有训练数据
- 预测阶段可能很慢
- 对不相关的功能和数据规模敏感
实践
Skelarn KNN参数概述
要使用sklearnKNN算法进行分类,我们需要先了解sklearnKNN算法的一些基本参数,那么这节就先介绍这些内容吧。
def KNeighborsClassifier(n_neighbors = 5,
weights='uniform',
algorithm = '',
leaf_size = '30',
p = 2,
metric = 'minkowski',
metric_params = None,
n_jobs = None
)
- n_neighbors:这个值就是指 KNN 中的 “K”了。前面说到过,通过调整 K 值,算法会有不同的效果。
- weights(权重):最普遍的 KNN 算法无论距离如何,权重都一样,但有时候我们想搞点特殊化,比如距离更近的点让它更加重要。这时候就需要 weight 这个参数了,这个参数有三个可选参数的值,决定了如何分配权重。参数选项如下:
- 'uniform':不管远近权重都一样,就是最普通的 KNN 算法的形式。
- 'distance':权重和距离成反比,距离预测目标越近则权重越高。
- 自定义函数:自定义一个函数,根据输入的坐标值返回对应的权重,达到自定义权重的目的。
- algorithm:在 sklearn 中,要构建 KNN 模型有三种构建方式,1. 暴力法,就是直接计算距离存储比较的那种放松。2. 使用 kd 树构建 KNN 模型 3. 使用球树构建。 其中暴力法适合数据较小的方式,否则效率会比较低。如果数据量比较大一般会选择用 KD 树构建 KNN 模型,而当 KD 树也比较慢的时候,则可以试试球树来构建 KNN。参数选项如下:
- 'brute' :蛮力实现
- 'kd_tree':KD 树实现 KNN
- 'ball_tree':球树实现 KNN
- 'auto': 默认参数,自动选择合适的方法构建模型
不过当数据较小或比较稀疏时,无论选择哪个最后都会使用 'brute'
- leaf_size:如果是选择蛮力实现,那么这个值是可以忽略的,当使用KD树或球树,它就是是停止建子树的叶子节点数量的阈值。默认30,但如果数据量增多这个参数需要增大,否则速度过慢不说,还容易过拟合。
- p:和metric结合使用的,当metric参数是"minkowski"的时候,p=1为曼哈顿距离, p=2为欧式距离。默认为p=2。
- metric:指定距离度量方法,一般都是使用欧式距离。
- 'euclidean' :欧式距离
- 'manhattan':曼哈顿距离
- 'chebyshev':切比雪夫距离
- 'minkowski': 闵可夫斯基距离,默认参数
- n_jobs:指定多少个CPU进行运算,默认是-1,也就是全部都算。
KNN代码实例
KNN算法算是机器学习里面最简单的算法之一了,我们来sklearn官方给出的例子,来看看KNN应该怎样使用吧:
数据集使用的是著名的鸢尾花数据集,用KNN来对它做分类。我们先看看鸢尾花长的啥样。
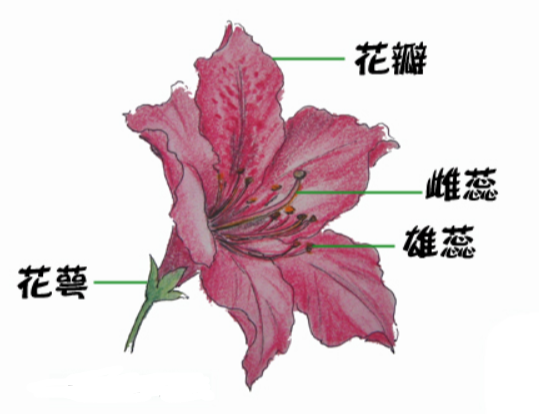
上面这个就是鸢尾花了,这个鸢尾花数据集主要包含了鸢尾花的花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性(特征),以及鸢尾花卉属于『Setosa,Versicolour,Virginica』三个种类中的哪一类(这三种都长什么样我也不知道)。
在使用KNN算法之前,我们要先决定K的值是多少,要选出最优的K值,可以使用sklearn中的交叉验证方法,代码如下:
#coding:utf-8
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
#读取鸢尾花数据集
iris = load_iris() # site-packages/sklearn/datasets/data/iris.csv
x = iris.data
y = iris.target
k_range = range(1, 31)
k_error = []
#循环,取k=1到k=31,查看误差效果
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
# cv参数决定数据集划分比例,这里是按照5:1划分训练集和测试集
# cross_val_score 方法解释参考网址 https://www.pianshen.com/article/403667100/
scores = cross_val_score(knn, x, y, cv=6, scoring='accuracy')
k_error.append(1 - scores.mean())
#画图,x轴为k值,y值为误差值
plt.plot(k_range, k_error)
plt.xlabel('Value of K for KNN')
plt.ylabel('Error')
plt.show()
运行后,我们可以得到下面这样的图:
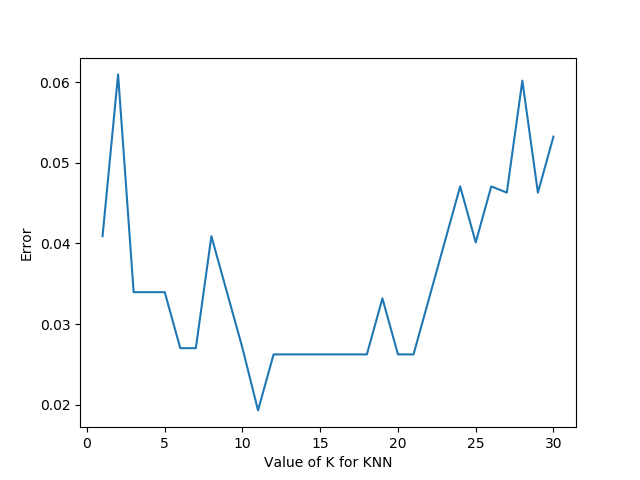
有了这张图,我们就能明显看出K值取多少的时候误差最小,这里明显是K=12最好。当然在实际问题中,如果数据集比较大,那为减少训练时间,K的取值范围可以缩小。
有了K值我们就能运行KNN算法了,具体代码如下:
# coding:utf-8
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
import numpy as np
from sklearn import neighbors, datasets
n_neighbors = 12
# 导入一些要玩的数据
iris = datasets.load_iris()
x = iris.data[:, :2] # 我们只采用前两个feature,方便画图在二维平面显示
y = iris.target
h = .02 # 网格中的步长
# 创建彩色的图
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
#weights是KNN模型中的一个参数,上述参数介绍中有介绍,这里绘制两种权重参数下KNN的效果图
for weights in ['uniform', 'distance']:
# 创建了一个knn分类器的实例,并拟合数据。
clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
clf.fit(x, y)
# 绘制决策边界。为此,我们将为每个分配一个颜色
# 来绘制网格中的点 [x_min, x_max]x[y_min, y_max].
x_min, x_max = x[:, 0].min() - 1, x[:, 0].max() + 1
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# 将结果放入一个彩色图中
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z.reshape(xx.shape),shading="auto", cmap=cmap_light)
# 绘制训练点
plt.scatter(x[:, 0], x[:, 1], c=y, cmap=cmap_bold)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("3-Class classification (k = %i, weights = '%s')"
% (n_neighbors, weights))
plt.show()
KNN和Kmeans 区别
前面说到过,KNN和Kmeans听起来有些像,但本质是有区别的,这里我们就顺便说一下两者的异同吧。
相同:
- K值都是重点
- 都需要计算平面中点的距离
相异:
- Knn和Kmeans的核心都是通过计算空间中点的距离来实现目的,只是他们的目的是不同的。KNN的最终目的是分类,而Kmeans的目的是给所有距离相近的点分配一个类别,也就是聚类。简单说,就是画一个圈,KNN是让进来圈子里的人变成自己人,Kmeans是让原本在圈内的人归成一类人。
参考网址
https://www.cnblogs.com/listenfwind/p/10311496.html https://www.cnblogs.com/listenfwind/p/10685192.html