摘要
随机森林(Random Forest)是一种由多个决策树组成的分类器,是一种监督学习算法,大部分时候是用bagging方法训练的。
bagging(bootstrap aggregating),训练多轮,每轮的样本由原始样本中随机可放回取出n个样本组成,最终的预测函数对分类问题采用投票方式。
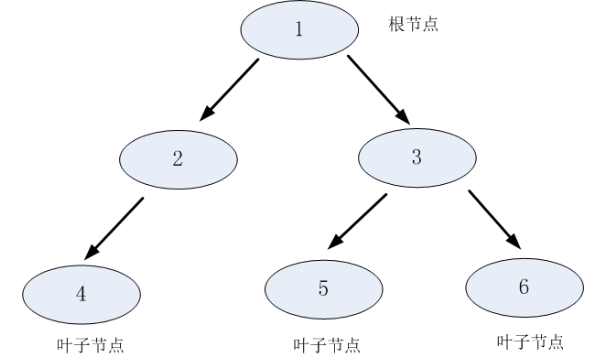
决策树利用如上图所示的树结构进行决策,每一个非叶子节点是一个判断条件,每一个叶子节点是结论。从根节点开始,经过多次判断得出结论,每一个决策树都是一个弱分类器。
决策树每次会选择一个属性进行判断,如果不能得出结论,继续选择其他属性进行判断,直到能够“肯定地”判断出用户的类型或者是属性都已经使用完毕。
核心思想就是在一个数据集中找到一个最优特征,然后通过最优特征约束循环寻找最优特征,直到满足指定条件为止。
最优特征一般是通过信息增益或信息增益率来确定,给定一批数据集,我们可以很容易得到它的不确定性(熵),经过一个特征的约束,数据的不确定性会降低。用两次不确定性值作差,代表不确定性降低量,降低的越多特征越好。
当数据的分类效果足够好了,比如当某个子节点内样本数目小于某一个指定值或树的最大深度达到某一个值,就可以停止了。
由上面介绍知:
bagging + 决策树 = 随机森林
比较典型的决策树有:ID3、C4.5、CART等
有两个点需要注意:
1、每个决策树的特征是有放回抽样选取的;
2、每棵树的训练数据是有返回抽样选取的;
参考网址
https://www.cnblogs.com/small-office/p/10246006.html