摘要
拟合出现的问题
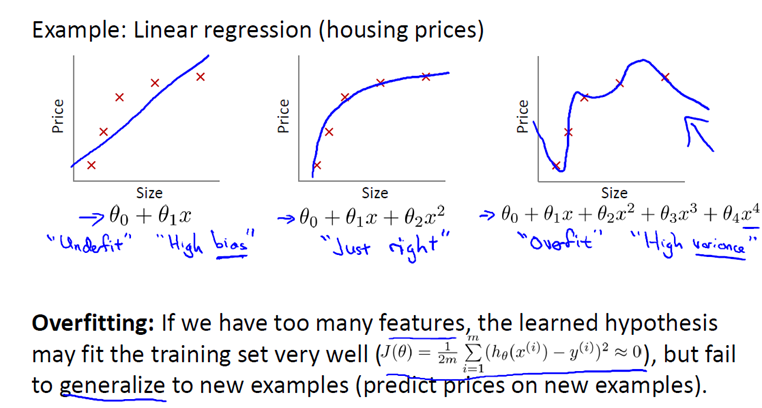
还是来看预测房价的这个例子,我们先对该数据做线性回归,也就是左边第一张图。
如果这么做,我们可以获得拟合数据的这样一条直线,但是,实际上这并不是一个很好的模型。我们看看这些数据,很明显,随着房子面积增大,住房价格的变化趋于稳定或者说越往右越平缓。因此线性回归并没有很好拟合训练数据。
我们把此类情况称为欠拟合(underfitting),或者叫作叫做高偏差(bias)。
这两种说法大致相似,都表示没有很好地拟合训练数据。高偏差这个词是 machine learning 的研究初期传下来的一个专业名词,具体到这个问题,意思就是说如果用线性回归这个算法去拟合训练数据,那么该算法实际上会产生一个非常大的偏差或者说存在一个很强的偏见。
第二幅图,我们在中间加入一个二次项,也就是说对于这幅数据我们用二次函数去拟合。自然,可以拟合出一条曲线,事实也证明这个拟合效果很好。
另一个极端情况是,如果在第三幅图中对于该数据集用一个四次多项式来拟合。因此在这里我们有五个参数θ0到θ4,这样我们同样可以拟合一条曲线,通过我们的五个训练样本,我们可以得到如右图的一条曲线。
一方面,我们似乎对训练数据做了一个很好的拟合,因为这条曲线通过了所有的训练实例。但是,这实际上是一条很扭曲的曲线,它不停上下波动。因此,事实上我们并不认为它是一个预测房价的好模型。
所以,我们把这类情况叫做过拟合(overfitting),也叫高方差(variance)。