大数据
大数据可以概括为5个V
- 数据量大(Volume)
- 速度快(Velocity)
- 类型多(Variety)
- 价值(Value)
- 真实性(Veracity)
大数据相关技术
- 大数据采集技术
- 大数据预处理技术
- 大数据存储及管理技术
- 大数据分析及挖掘技术
- 大数据展现与应用技术
大数据平台
- DataWorks(阿里云)
- hadoop(apache)
等
hadoop 不收费的发行版
Apache基金会hadoop
Hortonworks版本(Hortonworks Data Platform,简称“HDP”)
Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”)
最成型的发行版本,拥有最多的部署案例。提供强大的部署、管理和监控工具。Cloudera开发并贡献了可实时处理大数据的Impala项目。
社区版本与第三方发行版本的比较
Apache社区版本
优点:
- 完全开源免费。
- 社区活跃
- 文档、资料详实
缺点:
- 复杂的版本管理。版本管理比较混乱的,各种版本层出不穷,让很多使用者不知所措。
- 复杂的集群部署、安装、配置。通常按照集群需要编写大量的配置文件,分发到每一台节点上,容易出错,效率低下。
- 复杂的集群运维。对集群的监控,运维,需要安装第三方的其他软件,如ganglia,nagois等,运维难度较大。
- 复杂的生态环境。在Hadoop生态圈中,组件的选择、使用,比如Hive,Mahout,Sqoop,Flume,Spark,Oozie等等,需要大量考虑兼容性的问题,版本是否兼容,组件是否有冲突,编译是否能通过等。经常会浪费大量的时间去编译组件,解决版本冲突问题。
第三方发行版本(如CDH,HDP,MapR等)
优点:
- 基于Apache协议,100%开源。
- 版本管理清晰。比如Cloudera,CDH1,CDH2,CDH3,CDH4等,后面加上补丁版本,如CDH4.1.0 patch level 923.142,表示在原生态Apache Hadoop 0.20.2基础上添加了1065个patch。
- 比Apache Hadoop在兼容性、安全性、稳定性上有增强。第三方发行版通常都经过了大量的测试验证,有众多部署实例,大量的运行到各种生产环境。
- 版本更新快。通常情况,比如CDH每个季度会有一个update,每一年会有一个release。
- 基于稳定版本Apache Hadoop,并应用了最新Bug修复或Feature的patch
- 提供了部署、安装、配置工具,大大提高了集群部署的效率,可以在几个小时内部署好集群。运维简单。提供了管理、监控、诊断、配置修改的工具,管理配置方便,定位问题快速、准确,使运维工作简单,有效。
缺点:
涉及到厂商锁定的问题。(可以通过技术解决)
CDH 与 HDP 版本的比较
Cloudera:
最成型的发行版本,拥有最多的部署案例。提供强大的部署、管理和监控工具。Cloudera开发并贡献了可实时处理大数据的Impala项目。
Hortonworks:
不拥有任何私有(非开源)修改地使用了100%开源Apache Hadoop的唯一提供商。Hortonworks是第一家使用了Apache HCatalog的元数据服务特性的提供商。并且,它们的Stinger开创性地极大地优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Windows Server和Windows Azure在内的Microsft Windows平台上本地运行。
CDH,Apache Hadoop,HDP的比较
| Apache Hadoop | CDH | HDP | |
|---|---|---|---|
| 管理工具 | 手工 | Cloudera Manager | Ambari |
| 收费情况 | 开源 | 社区版免费,企业版收费 | 免费 |
hadoop 生态

hadoop 组件

hadoop 架构
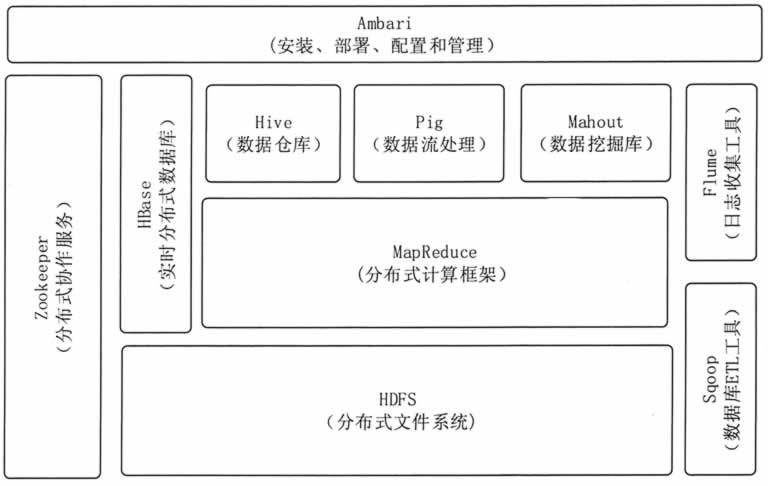
hadoop 生态各组件的作用
hadoop 的组件
-
HDFS:分布式文件系统,隐藏集群细节,可以看做一块儿超大硬盘
主:namenode, secondarynamenode
从:datanode
-
Yarn:分布式资源管理系统,用于同一管理集群中的资源(内存等)
主:ResourceManager
从:NodeManager
-
MapReduce:Hadoop的编程框架,用map和reduce方式实现分布式程序设计,类似于Spring。
Zookeeper
Zookeeper:分布式协调服务,用于维护集群配置的一致性、任务提交的事物性、集群中服务的地址管理、集群管理等
主:QuorumPeerMain
从:QuorumPeerMain
Hbase
Hbase:Hadoop下的分布式数据库,类似于NoSQL
主:HRegionserver,HMaster,HPeerMain(在使用zookeeper作为协调时没有此进程)
Hive
Hive:分布式数据仓库,让开发人员可以像使用SQL一样使用MR。
Sqoop
Sqoop:用于将传统数据库中数据导入到hbase中一个导入工具
Spark
Spark:基于内存的分布式处理框架
主:Mater
从:worker
Ambari
Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop和Hcatalog等。
运维常用命令
查看hdfs文件
- 显示文件名称
sudo -u hdfs hdfs dfs -ls /
- 创建文件夹
sudo -u hdfs hdfs dfs -mkdir /test
- 授权文件夹
sudo -u hdfs hdfs dfs -chmod -R 777 /test
- 修改所属用户组
sudo -u hdfs hdfs dfs -chown -R root:root /test
- 删除文件夹
sudo -u hdfs hdfs dfs -rm /test
hive查询命令
-
进入hive命令行界面
sudo -u hive hive -
查询存在的库名
show databases; -
查询数据库中的表
show tables in test; -
查询表结构
desc test.test; -
查询、插入、删除表、创建分区
yarn资源命令
-
查询正在运行的任务
sudo -u yarn yarn application -list -
查看正在运行的任务的日志
sudo -u yarn yarn logs -applicationId application_1607155116126_4519 -
切换队列
sudo -u yarn yarn application -movetoqueue application_1607155116126_4519 -queue default -
停止正在运行的任务
sudo -u yarn yarn application -kill application_1607155116126_0228