机器学习之朴素贝叶斯原理、实例与Python实现
机器学习之朴素贝叶斯原理、实例与Python实现
摘要
初步理解一下: 对于一组输入,根据这个输入,输出有多种可能性,需要计算每一种输出的可能性,以可能性最大的那个输出作为这个输入对应的输出。
那么,如何来解决这个问题呢?
贝叶斯给出了另一个思路。根据历史记录来进行判断。
思路是这样的:
1、根据贝叶斯公式:P(输出|输入)=P(输入|输出)*P(输出)/P(输入) 2、P(输入)=历史数据中,某个输入占所有样本的比例; 3、P(输出)=历史数据中,某个输出占所有样本的比例; 4、P(输入|输出)=历史数据中,某个输入,在某个输出的数量占所有样本的比例,例如:30岁,男性,中午吃面条,其中【30岁,男性就是输入】,【中午吃面条】就是输出。
条件概率的定义与贝叶斯公式

朴素贝叶斯分类算法
朴素贝叶斯是一种有监督的分类算法,可以进行二分类,或者多分类。一个数据集实例如下图所示:
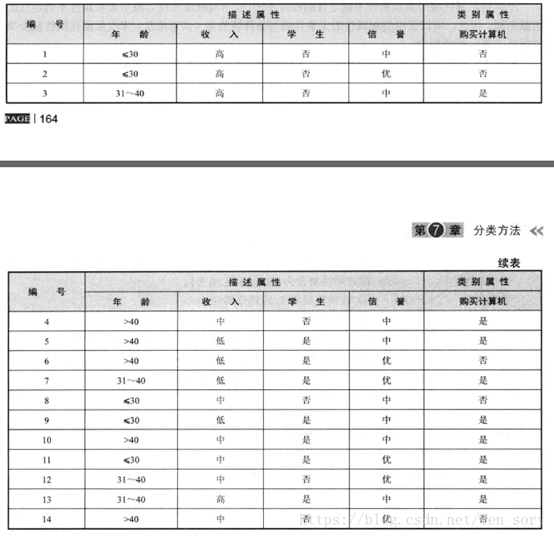
| 现在有一个新的样本, X = (年龄:<=30, 收入:中, 是否学生:是, 信誉:中),目标是利用朴素贝叶斯分类来进行分类。假设类别为C(c1=是 或 c2=否),那么我们的目标是求出P(c1 | X)和P(c2 | X),比较谁更大,那么就将X分为某个类。 |
下面,公式化朴素贝叶斯的分类过程。

实例
下面,将下面这个数据集作为训练集,对新的样本X = (年龄:<=30, 收入:中, 是否学生:是, 信誉:中) 作为测试样本,进行分类。
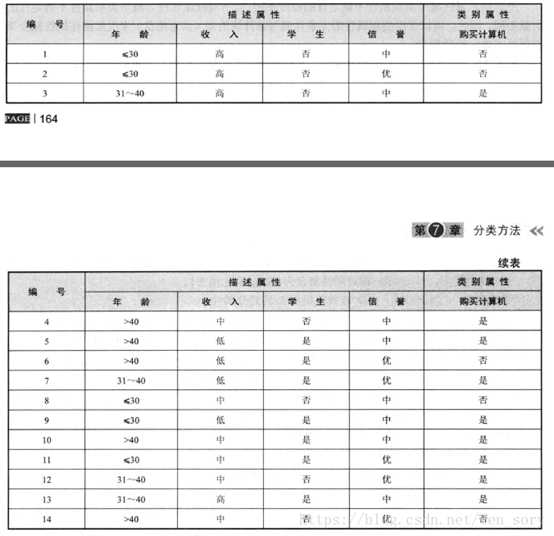
我们可以将这个实例中的描述属性和类别属性,与公式对应起来,然后计算。

参考python实现代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
#coding:utf-8
# 针对 “买电脑”实例进行朴素贝叶斯分类
#判断变量类型的函数
def typeof(variate):
type=None
if isinstance(variate,int):
type = "int"
elif isinstance(variate,str):
type = "str"
elif isinstance(variate,float):
type = "float"
elif isinstance(variate,list):
type = "list"
elif isinstance(variate,tuple):
type = "tuple"
elif isinstance(variate,dict):
type = "dict"
elif isinstance(variate,set):
type = "set"
return type
if __name__ == '__main__':
# 描述属性分别用数字替换
# 年龄, <=30-->0, 31~40-->1, >40-->2
# 收入, '低'-->0, '中'-->1, '高'-->2
# 是否学生, '是'-->0, '否'-->1
# 信誉: '中'-->0, '优'-->1
# 类别属性用数字替换
# 购买电脑是-->0, 不购买电脑否-->1
MAP = [{'<=30': 0, '31~40': 1, '>40': 2},
{'低': 0, '中': 1, '高': 2},
{'是': 0, '否': 1},
{'中': 0, '优': 1},
{'是': 0, '否': 1}]
# 训练样本
train_samples = ["<=30 高 否 中 否",
"<=30 高 否 优 否",
"31~40 高 否 中 是",
">40 中 否 中 是",
">40 低 是 中 是",
">40 低 是 优 否",
"31~40 低 是 优 是",
"<=30 中 否 中 否",
"<=30 低 是 中 是",
">40 中 是 中 是",
"<=30 中 是 优 是",
"31~40 中 否 优 是",
"31~40 高 是 中 是",
">40 中 否 优 否"]
# 下面步骤将文字,转化为对应数字
# print(typeof(train_samples)) # list
# print(train_samples) # ['<=30 高 否 中 否', '<=30 高 否 优 否', '31~40 高 否 中 是', '>40 中 否 中 是', '>40 低 是 中 是', '>40 低 是 优 否', '31~40 低 是 优 是', '<=30 中 否 中 否', '<=30 低 是 中 是', '>40 中 是 中 是', '<=30 中 是 优 是', '31~40 中 否 优 是', '31~40 高 是 中 是', '>40 中 否 优 否']
train_samples = [sample.split(' ') for sample in train_samples]
# print(typeof(train_samples[1])) # list
# print(train_samples[1]) # ['<=30', '高', '否', '优', '否']
# print(typeof(train_samples)) # list
# print(train_samples) # [['<=30', '高', '否', '中', '否'], ['<=30', '高', '否', '优', '否'], ['31~40', '高', '否', '中', '是'], ['>40', '中', '否', '中', '是'], ['>40', '低', '是', '中', '是'], ['>40', '低', '是', '优', '否'], ['31~40', '低', '是', '优', '是'], ['<=30', '中', '否', '中', '否'], ['<=30', '低', '是', '中', '是'], ['>40', '中', '是', '中', '是'], ['<=30', '中', '是', '优', '是'], ['31~40', '中', '否', '优', '是'], ['31~40', '高', '是', '中', '是'], ['>40', '中', '否', '优', '否']]
# exit()
train_samples = [[MAP[i][attr] for i, attr in enumerate(sample)] for sample in train_samples]
# print(train_samples) # [[0, 2, 1, 0, 1], [0, 2, 1, 1, 1], [1, 2, 1, 0, 0], [2, 1, 1, 0, 0], [2, 0, 0, 0, 0], [2, 0, 0, 1, 1], [1, 0, 0, 1, 0], [0, 1, 1, 0, 1], [0, 0, 0, 0, 0], [2, 1, 0, 0, 0], [0, 1, 0, 1, 0], [1, 1, 1, 1, 0], [1, 2, 0, 0, 0], [2, 1, 1, 1, 1]]
# 待分类样本
X = '<=30 中 是 中'
X = [MAP[i][attr] for i, attr in enumerate(X.split(' '))]
# 训练样本数量
n_sample = len(train_samples)
# print(n_sample) # 14
# 单个样本的维度: 描述属性和类别属性个数
dim_sample = len(train_samples[0])
# print(dim_sample) # 5
# 计算每个属性有哪些取值
attr = []
for i in range(0, dim_sample):
attr.append([])
# print(attr) # [[], [], [], [], []]
for sample in train_samples:
for i in range(0, dim_sample):
if sample[i] not in attr[i]:
attr[i].append(sample[i])
# print(attr) # [[0, 1, 2], [2, 1, 0], [1, 0], [0, 1], [1, 0]]
# 每个属性取值的个数
n_attr = [len(attr) for attr in attr]
# print(n_attr) # [3, 3, 2, 2, 2]
# 记录不同类别的样本个数
n_c = []
for i in range(0, n_attr[dim_sample - 1]):
n_c.append(0)
# print(n_c) # [0, 0]
# 计算不同类别的样本个数 不同分类包含有无电脑
for sample in train_samples:
n_c[sample[dim_sample - 1]] += 1
# print(n_c) # [9, 5]
# 计算不同类别样本所占概率
p_c = [n_cx / sum(n_c) for n_cx in n_c]
# print(p_c) # [0.6428571428571429, 0.35714285714285715]
# 将用户按照类别分类
samples_at_c = {}
for c in attr[dim_sample - 1]:
samples_at_c[c] = []
# print(samples_at_c) # {1: [], 0: []}
for sample in train_samples:
samples_at_c[sample[dim_sample - 1]].append(sample)
# print(samples_at_c) # {1: [[0, 2, 1, 0, 1], [0, 2, 1, 1, 1], [2, 0, 0, 1, 1], [0, 1, 1, 0, 1], [2, 1, 1, 1, 1]], 0: [[1, 2, 1, 0, 0], [2, 1, 1, 0, 0], [2, 0, 0, 0, 0], [1, 0, 0, 1, 0], [0, 0, 0, 0, 0], [2, 1, 0, 0, 0], [0, 1, 0, 1, 0], [1, 1, 1, 1, 0], [1, 2, 0, 0, 0]]}
# 记录 每个类别的训练样本中,取待分类样本的某个属性值的样本个数
n_attr_X = {}
for c in attr[dim_sample - 1]:
n_attr_X[c] = []
for j in range(0, dim_sample - 1):
n_attr_X[c].append(0)
# print(len(range(0, dim_sample - 1))) # 4
# print(n_attr_X) # {1: [0, 0, 0, 0], 0: [0, 0, 0, 0]}
# 计算 每个类别的训练样本中,取待分类样本的某个属性值的样本个数
for c, samples_at_cx in zip(samples_at_c.keys(), samples_at_c.values()):
for sample in samples_at_cx:
for i in range(0, dim_sample - 1):
if X[i] == sample[i]:
n_attr_X[c][i] += 1
# print(n_attr_X) # {1: [3, 2, 1, 2], 0: [2, 4, 6, 6]}
# 字典转化为list
n_attr_X = list(n_attr_X.values())
# print(n_attr_X) # [[3, 2, 1, 2], [2, 4, 6, 6]]
# 存储最终的概率
result_p = []
for i in range(0, n_attr[dim_sample - 1]):
result_p.append(p_c[i])
# print(result_p) # [0.6428571428571429, 0.35714285714285715]
# 计算概率
print(n_attr)
print(n_attr_X)
print(n_c)
for i in range(0, n_attr[dim_sample - 1]):
n_attr_X[i] = [x / n_c[i] for x in n_attr_X[i]]
print(n_attr_X)
for x in n_attr_X[i]:
result_p[i] *= x
# print('概率分别为', result_p) # 概率分别为 [0.0011757789535567313, 0.16457142857142862]
# 找到概率最大对应的那个类别,就是预测样本的分类情况
print(max(result_p))
predict_class = result_p.index(max(result_p))
# print(predict_class) # 1
参考网址
本文由作者按照 CC BY 4.0 进行授权